In the last few months I’ve been working on a rendering engine capable of rendering an entire planet. I’ve seen many solutions for procedural planet rendering (generating the height map on the fly), so I was focusing on a different problem: how to render a planet using already existing elevation data, and which is the most efficient way to store that data at large scale.
Sources
- For development/debug/demonstration purposes I’ve been using the elevation data of the Earth available at http://viewfinderpanoramas.org/dem3.html. I use the 3 arc second version which has full coverage.
- For texturing, I use the images available at https://www.h-schmidt.net/map/.
- For loading the textures in jpeg I use Sean Barrett’s stb_image.h from https://github.com/nothings/stb.
- For rendering the atmosphere I implemented the algorithm described in the article https://hal.inria.fr/inria-00288758/document. (I haven’t implemented everything from here, for example there are no light shafts yet.)
Performance
I measured the performance on my (at this point, quite weak) laptop:
CPU: i7-6700HQ 2.6 GHz
GPU: NVIDIA Geforce GTX 950M, 4 GB
HDD: 1TB, 7200 RPM
First, some words about the rendering: the geometry is divided into meshlets (triangle batches containing 64 triangles) to make the pipeline suitable for mesh shaders, and to allow further optimizations like meshlet-culling which is not implemented yet. Currently, there is space allocated for 16384 meshlets, and the “culling” shader doesn’t do much, only decides which meshlet slots are active, and fills the indirect command arguments accordingly.

I measured the GPU performance using PIX. Rendering the above frame (during movement) takes about 11 ms. Most of it (~9.5 ms) is spent in the ExecuteIndirect call that draws the planet with a simple forward rendering method, at the moment. Sky rendering is ~1 ms. The remaining 0.5 ms is for resource barriers and generating new requested meshlets (vertices, normals, uv coords).
The tessellation, lod selection is done by the CPU, on the main thread. I measured the lod update with _rdtsc(). The results were unfortunately quite unstable, but it’s worth noting that the measured cycles were almost always below 1.5 million cycles, even when travelling with high speed close to the ground. When the camera is way above the ground, like in the beginning of the video, the measured values are around 100-200 thousand cycles.
It’s important to note that the loading of the height data from file to gpu memory happens on a different thread, only the requests get issued on the main thread.
Tools
Beside the main program, I made some tools for various purpose, I’ll describe them briefly.
- Shader Compiler: putting together a graphics (even a compute) pipeline in D3D12, allocating descriptor tables, setting the descriptors, binding the descriptor tables, setting root constants could be a pain in the ass. It’s not the worst thing in the world, but it’s better to have something that fprintfs some C++ code based on a short description of the layout, rasterizer settings, render targets, depth-stencil state, struct definitions in hlsl, etc… That’s what this tool does. Also, it compiles the HLSL code using D3DCompile(). Every other program that has shaders uses this tool to compile them.
- Height Generator: this tool converts the raw elevation data organized in HGT files to the format I use directly for rendering. After developing, and debugging it, it took ~24 hours to generate the necessary data with it.
- Sky Generator: this tool is for generating the textures required for sky rendering and aerial perspective.
Design Philosophy, Coding
Working on this project the main focus was on designing algorithms, data structures while taking account the capabilities of the hardware. So the focus was not on coding, in fact I wanted to avoid code-related design issues at all. For this I had two major “rules”:
- Making sure that iteration is as fast as possible, that is, I can change algorithms, data structures, hard-coded constants quickly without thinking about the code and waiting for compilation too much.
- Writing easily understandable code, that is, by looking at the code it should be relatively easy to figure out what the hardware does when runs that code, what data it loads, how it modifies it, and what data it writes.
In order to achieve these, I don’t use templates, STL, the concept of RAII, or any third party library beside the Win32 API, D3D12, XInput, stb_image.h, and some standard C functions (math functions, functions for string manipulations, memcpy). I use lot’s of raw pointers, relative pointers and plane old data structures with global functions. I have only one compilation unit per program which can be built by running a batch file. For text-editor and debugger I use Visual Studio 2017.
With these concepts, I can compile the main program and the tools from scratch in about 2-3 second per program, using -Od (with -O2 it takes only slightly longer).
 be an oriented, differentiable 2-manifold, and
be an oriented, differentiable 2-manifold, and  its Gauss map (where
its Gauss map (where  is the 2-sphere). For such a surface let
is the 2-sphere). For such a surface let  be the volume form generated by the embedding
be the volume form generated by the embedding  , that is,
, that is, 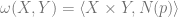 for
for 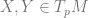 . Let’s assume
. Let’s assume  is invertible. The normal distribution
is invertible. The normal distribution  of
of 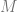 is defined by the equation
is defined by the equation
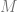 along a given direction
along a given direction  . The projection associated to
. The projection associated to  can be defined by the volume form
can be defined by the volume form  ,
,  . The projected area of
. The projected area of 

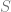 is a symmetric, positive definite matrix with eigenvalues
is a symmetric, positive definite matrix with eigenvalues 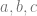 , which are the sizes of the main axes of
, which are the sizes of the main axes of  . For a given
. For a given 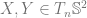 such that
such that 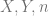 form an orthonormal basis of
form an orthonormal basis of  . Then we have
. Then we have  ,
,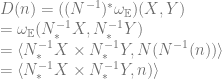
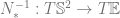 . This map is the multiplication by the Jacobian of
. This map is the multiplication by the Jacobian of 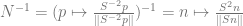 .
. ,
,
 is an orthonormal basis. Putting these together, we have
is an orthonormal basis. Putting these together, we have
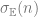 . Note that the matrix
. Note that the matrix 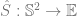 .
. 
 , a simple calculation shows that
, a simple calculation shows that 
 , we have
, we have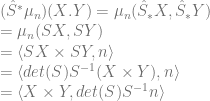
 for some function
for some function 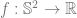 . We can compute
. We can compute 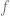 by, for example, choosing a point
by, for example, choosing a point  and
and 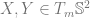 such that
such that  form an orthonormal basis. Then
form an orthonormal basis. Then  , so
, so
 , we have
, we have  , and the projected area is
, and the projected area is
 nanoseconds is about
nanoseconds is about  years, overflow is basically impossible in practice.
years, overflow is basically impossible in practice.![h: [0,1]^2\rightarrow\mathbb{R}](https://s0.wp.com/latex.php?latex=h%3A+%5B0%2C1%5D%5E2%5Crightarrow%5Cmathbb%7BR%7D&bg=ffffff&fg=666666&s=0&c=20201002) function. Let’s assume that this function is smooth. The graph of this function,
function. Let’s assume that this function is smooth. The graph of this function, ![\tilde{h}: [0,1]^2\rightarrow\mathbb{R}^3](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bh%7D%3A+%5B0%2C1%5D%5E2%5Crightarrow%5Cmathbb%7BR%7D%5E3++&bg=ffffff&fg=666666&s=0&c=20201002) ,
,  defines a smooth surface in
defines a smooth surface in 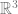 .
.  ? To calculate that, we can take the cross product of the tangent and bitangent vectors, and normalize the result. So, for the unnormalized normal vector (denoted by
? To calculate that, we can take the cross product of the tangent and bitangent vectors, and normalize the result. So, for the unnormalized normal vector (denoted by 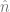 ) we have
) we have
 . Now, what happens if we scale the height map by some number
. Now, what happens if we scale the height map by some number  , that is, we consider the height map
, that is, we consider the height map  ? The partial derivatives will get multiplied by
? The partial derivatives will get multiplied by  as well, so to compute the new normal from the old one, we have to do the following steps:
as well, so to compute the new normal from the old one, we have to do the following steps:![r: [0,1]^2\rightarrow\mathbb{R}^3](https://s0.wp.com/latex.php?latex=r%3A+%5B0%2C1%5D%5E2%5Crightarrow%5Cmathbb%7BR%7D%5E3++&bg=ffffff&fg=666666&s=0&c=20201002) . As I wrote at the end of the previous post, we can assume that the texture coordinates of a point
. As I wrote at the end of the previous post, we can assume that the texture coordinates of a point  is
is  . We also have a height map
. We also have a height map ![h: [0,1]^2\rightarrow\mathbb{R}](https://s0.wp.com/latex.php?latex=h%3A+%5B0%2C1%5D%5E2%5Crightarrow%5Cmathbb%7BR%7D++&bg=ffffff&fg=666666&s=0&c=20201002) . Let’s define the function
. Let’s define the function ![n: [0,1]^2\rightarrow\mathbb{R}^3](https://s0.wp.com/latex.php?latex=n%3A+%5B0%2C1%5D%5E2%5Crightarrow%5Cmathbb%7BR%7D%5E3++&bg=ffffff&fg=666666&s=0&c=20201002) in a way that
in a way that  is the normal vector of the surface at the point
is the normal vector of the surface at the point  .) From
.) From  and
and  by offsetting the surface
by offsetting the surface 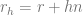 .
. . The terms look familiar, except for one: we haven’t seen the
. The terms look familiar, except for one: we haven’t seen the 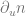 term yet. This term represents how the normal vector changes if we move along the tangent direction on the surface. It can be viewed as a second order term for describing the surface (the first order terms are the tangent and bitangent vectors), and can be computed from the first and second partial derivatives of the surface
term yet. This term represents how the normal vector changes if we move along the tangent direction on the surface. It can be viewed as a second order term for describing the surface (the first order terms are the tangent and bitangent vectors), and can be computed from the first and second partial derivatives of the surface  which for the surface
which for the surface 
 denotes the usual scalar product on
denotes the usual scalar product on 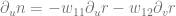 . (Don’t care about the negative sign, let’s just accept it as a convention.) So for the tangent vector of the offset surface we have
. (Don’t care about the negative sign, let’s just accept it as a convention.) So for the tangent vector of the offset surface we have
![= \left[TBN\right] \begin{pmatrix} 1-hw_{11} \\ -hw_{12} \\ \partial_uh \end{pmatrix}](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++1-hw_%7B11%7D+%5C%5C++-hw_%7B12%7D+%5C%5C++%5Cpartial_uh+%5Cend%7Bpmatrix%7D++&bg=ffffff&fg=666666&s=0&c=20201002) ,
,![\left[TBN\right] = (\partial_ur, \partial_vr, n)](https://s0.wp.com/latex.php?latex=%5Cleft%5BTBN%5Cright%5D++%3D+%28%5Cpartial_ur%2C+%5Cpartial_vr%2C+n%29++&bg=ffffff&fg=666666&s=0&c=20201002) is the usual (but not orthogonalized!) TBN matrix. Similarly, for the bitangent vector of the offset surface we have
is the usual (but not orthogonalized!) TBN matrix. Similarly, for the bitangent vector of the offset surface we have![\partial_vr_h = \left[TBN\right] \begin{pmatrix} -hw_{21} \\ 1-w_{22} \\ \partial_vh \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Cpartial_vr_h+%3D+++%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++-hw_%7B21%7D+%5C%5C++1-w_%7B22%7D+%5C%5C++%5Cpartial_vh+++%5Cend%7Bpmatrix%7D++&bg=ffffff&fg=666666&s=0&c=20201002) .
.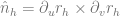 , and normalizing that we get the required normal vector
, and normalizing that we get the required normal vector  .
. .
.![\partial_ur_h = \left[TBN\right] \begin{pmatrix} 1 \\ 0 \\ \partial_uh \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Cpartial_ur_h+%3D+++%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++1+%5C%5C++0+%5C%5C++%5Cpartial_uh+++%5Cend%7Bpmatrix%7D++&bg=ffffff&fg=666666&s=0&c=20201002) , and
, and ![\partial_vr_h = \left[TBN\right] \begin{pmatrix} 0 \\ 1 \\ \partial_vh \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Cpartial_vr_h+%3D+++%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++0++%5C%5C++1+%5C%5C++%5Cpartial_vh+++%5Cend%7Bpmatrix%7D++&bg=ffffff&fg=666666&s=0&c=20201002) .
.![\hat{n}_h=\left( \left[TBN\right] \begin{pmatrix} 1 \\ 0 \\ \partial_uh \end{pmatrix} \right) \times \left( \left[TBN\right] \begin{pmatrix} 0 \\ 1 \\ \partial_vh \end{pmatrix} \right) = \left[TBN\right] \left( \begin{pmatrix} 1 \\ 0 \\ \partial_uh \end{pmatrix} \times \begin{pmatrix} 0 \\ 1 \\ \partial_vh \end{pmatrix} \right)](https://s0.wp.com/latex.php?latex=%5Chat%7Bn%7D_h%3D%5Cleft%28++%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++1++%5C%5C++0+%5C%5C++%5Cpartial_uh+++%5Cend%7Bpmatrix%7D++%5Cright%29+%5Ctimes+%5Cleft%28++%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++0++%5C%5C++1+%5C%5C++%5Cpartial_vh+++%5Cend%7Bpmatrix%7D++%5Cright%29+%3D++%5Cleft%5BTBN%5Cright%5D++%5Cleft%28+%5Cbegin%7Bpmatrix%7D++1++%5C%5C++0+%5C%5C++%5Cpartial_uh+++%5Cend%7Bpmatrix%7D++%5Ctimes++%5Cbegin%7Bpmatrix%7D++0++%5C%5C++1+%5C%5C++%5Cpartial_vh+++%5Cend%7Bpmatrix%7D+%5Cright%29++&bg=ffffff&fg=666666&s=0&c=20201002)
![= \left[TBN\right] \begin{pmatrix} -\partial_uh \\ -\partial_vh \\ 1 \end{pmatrix}](https://s0.wp.com/latex.php?latex=%3D++%5Cleft%5BTBN%5Cright%5D+%5Cbegin%7Bpmatrix%7D++-%5Cpartial_uh++%5C%5C++-%5Cpartial_vh+%5C%5C++1+++%5Cend%7Bpmatrix%7D++&bg=ffffff&fg=666666&s=0&c=20201002) .
. function, which is the parametrization of our surface, where
function, which is the parametrization of our surface, where  is some 2-dimensional subset of
is some 2-dimensional subset of  , and also, we have a
, and also, we have a ![t: A\rightarrow [0,1]^2](https://s0.wp.com/latex.php?latex=t%3A+A%5Crightarrow+%5B0%2C1%5D%5E2++&bg=ffffff&fg=666666&s=0&c=20201002) function, which gives the texture coordinates (uv coordinates) of the surface; then the tangent and bitangent vectors are the first and second colums of the matrix
function, which gives the texture coordinates (uv coordinates) of the surface; then the tangent and bitangent vectors are the first and second colums of the matrix 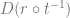 , respectively. (For a function
, respectively. (For a function  , let’s denote its Jacobi matrix by
, let’s denote its Jacobi matrix by 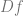 .) Note, that
.) Note, that  .
. 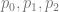 , and with correspondig texture coordinates
, and with correspondig texture coordinates  . Then both
. Then both 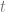 are just parametrizations of triangles, namely
are just parametrizations of triangles, namely  is the triangle whose vertices are
is the triangle whose vertices are 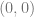 ,
,  and
and 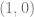 ,
,  , and
, and 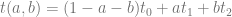 .
. and
and 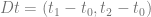 , so the tangent and bitangent vectors are the columns of the matrix
, so the tangent and bitangent vectors are the columns of the matrix  . This expression is usually used to calculate the tangent and bitangent vectors for a triangulated mesh at the vertices
. This expression is usually used to calculate the tangent and bitangent vectors for a triangulated mesh at the vertices  . Of course, a vertex can be a vertex of more than one triangles (and usually is). In that case, for a vertex we can simply take the average of the tangent and bitangent vectors computed for the triangles containing that vertex. It’s important to note that the normal vector is always perpendicular to both tangent vector (after all, this is how the normal vector is defined), so we have to make the averaged tangent and bitangent vectors perpendicular to the normal vector.
. Of course, a vertex can be a vertex of more than one triangles (and usually is). In that case, for a vertex we can simply take the average of the tangent and bitangent vectors computed for the triangles containing that vertex. It’s important to note that the normal vector is always perpendicular to both tangent vector (after all, this is how the normal vector is defined), so we have to make the averaged tangent and bitangent vectors perpendicular to the normal vector. are orthonormal. Intuitively, this just means that we have to unfold the surface, flatten it without any stretching. If that can be done, it’s great, but it’s usually not the case. Without going into details, I mention that for a smooth surface, such
are orthonormal. Intuitively, this just means that we have to unfold the surface, flatten it without any stretching. If that can be done, it’s great, but it’s usually not the case. Without going into details, I mention that for a smooth surface, such 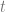 exists only if the surface has zero Gaussian curvature, and that’s just simply not the case for most surfaces.
exists only if the surface has zero Gaussian curvature, and that’s just simply not the case for most surfaces. ![r:[0,1]^2\rightarrow\mathbb{R}^3](https://s0.wp.com/latex.php?latex=r%3A%5B0%2C1%5D%5E2%5Crightarrow%5Cmathbb%7BR%7D%5E3++&bg=ffffff&fg=666666&s=0&c=20201002) , and the texture coordinates of the point
, and the texture coordinates of the point  . This simplifies things a little bit, since then, the tangent vector is
. This simplifies things a little bit, since then, the tangent vector is  , and the bitangent vector is
, and the bitangent vector is  . In the next post, I will assume that this holds for
. In the next post, I will assume that this holds for 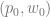 ,
,  ,
,  with some corresponding vertex attributes
with some corresponding vertex attributes  ,
,  ,
,  (e.g. texture coordinates, color, normal). After perspective divison we have
(e.g. texture coordinates, color, normal). After perspective divison we have 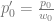 ,
,  ,
,  . Let’s have
. Let’s have 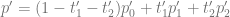 . The question is, how should we compute the proper vertex attribute
. The question is, how should we compute the proper vertex attribute  corresponding to
corresponding to  ?
?  . Then, of course, the vertex attribute corresponding to
. Then, of course, the vertex attribute corresponding to 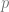 is simply
is simply  . Now, what is the point
. Now, what is the point  we have
we have 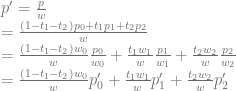
 ,
,  and
and 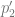 is
is 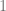 . So by setting
. So by setting  and
and  , we can write
, we can write  .
.  , where
, where  and
and 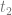 can be computed from the two equations
can be computed from the two equations  , and
, and  ,
, . We can go further by substituting
. We can go further by substituting 
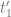 and
and 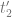 values (that is, basically, for a given pixel inside the triangle) we calculate
values (that is, basically, for a given pixel inside the triangle) we calculate  , we compute the corresponding
, we compute the corresponding 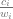 values, and use them to calculate the vertex attributes directly from given
values, and use them to calculate the vertex attributes directly from given 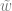 as well.
as well.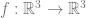 be a differentiable function, and
be a differentiable function, and  is a smooth surface. Let’s denote the image of
is a smooth surface. Let’s denote the image of  . If
. If 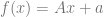 , where
, where  is a vector, and
is a vector, and  is an invertible matrix. Then,
is an invertible matrix. Then, 
 and
and  curves referenced in the text.
curves referenced in the text. 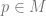 . Let’s denote the tangent plane of
. Let’s denote the tangent plane of  by
by  . Similarly, let
. Similarly, let  and
and  be the tangent plane of
be the tangent plane of 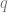 . Let’s define first how the tangent vectors in
. Let’s define first how the tangent vectors in  function from
function from  vector. We can represent this vector with a small piece of curve
vector. We can represent this vector with a small piece of curve 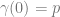 and
and  . Now let’s apply
. Now let’s apply  , so by taking the derivative of
, so by taking the derivative of  , we get a vector
, we get a vector  . And that’s what we wanted! That is
. And that’s what we wanted! That is  . Let’s calculate it, using the chain rule for derivation
. Let’s calculate it, using the chain rule for derivation ,
, is the Jacobi matrix of
is the Jacobi matrix of  is a linear transformation, it is the multiplication by
is a linear transformation, it is the multiplication by  , therefore, the Jacobi matrix is constant, it is
, therefore, the Jacobi matrix is constant, it is  in the following. First, what is the normal vector
in the following. First, what is the normal vector 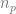 of
of  of
of 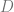 is invertible. In this case, for every vector
is invertible. In this case, for every vector 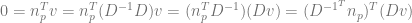 .
. for some
for some  ). So we got that the vector
). So we got that the vector  is perpendicular to
is perpendicular to  .
.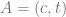 can be viewed as a transparent light source where
can be viewed as a transparent light source where  is the emittance and
is the emittance and  is the transparency. Then
is the transparency. Then  results in the color
results in the color 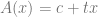 , that is, it absorbs some light, and adds to the remaining light its own emittance value . This is just the blend equation using premultiplied alpha. Because of that, premultiplied alpha seems a more physically plausible blending, than non-premultiplied alpha.
, that is, it absorbs some light, and adds to the remaining light its own emittance value . This is just the blend equation using premultiplied alpha. Because of that, premultiplied alpha seems a more physically plausible blending, than non-premultiplied alpha. and
and  an apply them to the color
an apply them to the color 
 we have
we have  . This shows how to blend images together. Expressing the transparencies with the alpha channels, we got the blend equation for the alpha channel
. This shows how to blend images together. Expressing the transparencies with the alpha channels, we got the blend equation for the alpha channel
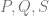 we have
we have  . The blending above is by definition associative, since it was defined simply by function composition, which is always associative.
. The blending above is by definition associative, since it was defined simply by function composition, which is always associative.